

Databases are of one of the most common features of a tech project, but for non-techies it can seem a little overwhelming. There are literally hundreds of databases – but why? Aren’t they just a place to store data? Why so many types, with so many silly names (I mean, MongoDB? Really?) Why does it matter which database the tech teams are using?
In this article we’ll cover this at a high level – we’ll skim over the different types (well, the main ones you’ll encounter anyway) and we’ll cover what makes them ideal for different tasks. Let’s dive in shall we?
Types Of Database
Let’s start by covering the very basic idea of a database. The most common and easy-to-understand type is a relational database, so we’ll start there. If you’re familiar with Excel, or Google sheets, this will look very familiar.
Relational Databases
This is the sort of picture you’d have if you did a very basic database course:

In the diagram we have three building blocks for a database. A database contains tables – which are like a spreadsheet with rows and columns. Each row has multiple entries, one in each column. A single entry in one space on the row is called a field (think of a cell in a spreadsheet).
So you might have a table called “employees”, each row (called a “record”) represents a single employee, and each column in the row is a field, representing some aspect of that employee – name, company id, start date, etc.
So far, so simple.
Of course, its not really that simple.
In large, complex databases you have much more complicated structures, with tables linking to each other in way more complicated ways than in the diagram below:
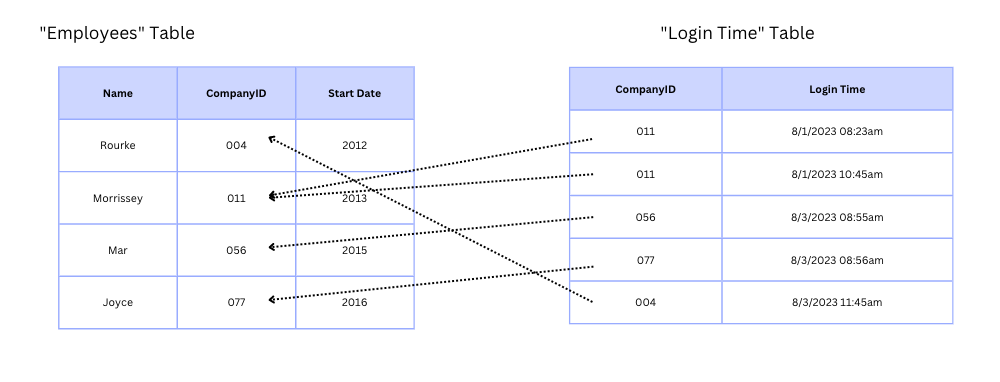
But you get the idea, right?
One table has all the employees, the other shows when a given employee logged into our super-secure system. Ahem.
Since the full picture of the data is defined by relationships between the tables, this type of database is known as (surprise!) a relational database.
Jargon Alert: Separating all the details out into different tables to minimize the amount of duplication (e.g. the employee name, address, etc is in one table, and the other table just stores the employee id to go look them up) is called normalization.
Rather than write out the employee details each time, we simply store the time the person logged in, and their company id. If we want to generate a snazzy report showing all the times a particular employee logged in this month, with more of their details, we pull those details from the employees table by looking them up based on their id.
Why bother with this? Two reasons really.
It used to be extremely expensive to store data. Disk drives were expensive, and normalized data takes up less space. It’s also far more efficient when updating data to only have to touch one place. Imagine if employee names and addresses were copied all over the place – in the access log, in the timesheets table, in the salary tables … you’d have to update multiple records when someone moved house.
That might not sound too terrible – but in a more real-time system where thousands of updates are happening every second, it would be slow – and worse, could lead to inconsistencies if one table had been updated but another hadn’t.
Jargon Alert: A term you might hear is that a database is “ACID compliant”. ACID stands for Atomicity, Consistency, Isolation, and Durability. Without going into crazy detail, that basically means the way the database is implemented means you can guarantee that updates will happen consistently – no-one will ever see a partly-updated database.
Some common examples of ACID-compliant relational databases: MySQL, PostgreSQL, and Oracle DB.
This might seem like a no-brainer, right? Why would you ever want to build a database where the data was not guaranteed to be consistent and up-to-date?
Well, actually (you’ll be shocked to hear this I’m sure) there is a whole category of databases that deliberately take a different approach.
They’re called NoSQL databases, because … because they don’t support SQL.
(insert record scratch sound here)
SQL?
OK, let’s cover that now.
SQL – The Lingua Franca Of Relational Databases
There are only really four things you want to be able to do with data in a database:
- Create new tables and records
- Retrieve existing records
- Update existing records
- Delete Records
The more observant readers, especially those who have worked with tech people before, will notice that forms the acronym CRUD.
Of course it does.
(Yes, tech people really do use that acronym.)
SQL is a language used to perform those actions on databases (it actually stands for Structured Query Language.)
I won’t go into huge detail, but here’s some examples. Let’s assume we have a table of song information called “Music”, with columns of a unique song id, song name, artist, year, etc).

Let’s create a new record (i.e. a new row in the table):
INSERT INTO Music (SongID, SongName, Artist, Album, Year)
VALUES ("1984-012-WQ", 'How Soon Is Now?', 'The Smiths', 'Hatful of Hollow', 1984);
As you can see, SQL is pretty readable. Let’s retrieve all the 80s songs from our table (because that’s the best decade for music):
SELECT SongName, Artist FROM Music WHERE Year >= 1980 AND Year < 1990;
Other commands are (duh) UPDATE, DELETE…
Obviously it gets more complicated than that when you have to do things like JOIN across multiple tables to decide which records you need, but those are the building blocks above.
OK – now for something completely different.
NoSQL Databases
What we’ve been looking at so far is highly structured data. Every row in the database is the same, has the same fields, and so on. So for the music example above, every song has an artist, every song has a year of release, etc.
But – most of the data in the world is unstructured data, or at least, semi-structured.
Emails, Text Files, Social Media feeds, … the world is drowning in data. It’s a scientific fact that 98.7% of all data created in human history was created since last Thursday.
OK, I made that up. But it’s directionally correct, and that’s what counts. We’ve been creating ridiculous volumes of mostly-unstructured data in the last few years.
Let’s stick with the music example and talk through this a bit, because it gets confusing, and people often use the terms in a very imprecise way.
So if we assume that artist name, song name, year of release are all structured data, a good example of unstructured data would be lyrics. If you have a single text entry for the lyrics of each song, then you know where to find it – but likely nothing else.
What sort of structure could you use to describe song lyrics? Well, how about verse 1, chorus, verse 2, chorus, etc? Would that work?
Let’s see that in the relational table:

You can see the problem straight away, right?
Not every song has the same structure. Not every song has a chorus, maybe one song has two verses before the chorus kicks in, and so on.
That’s just one example, but with other data sources (like social media feeds) evolving rapidly and changing their structure all the time to add new features, its clear there are a lot of applications that simply don’t make sense to shoehorn into an old-school table structure.
So naturally, a set of databases began to pop up designed to make it easier to store and retrieve this sort of data where the structure is changing all the time.
Some examples are MongoDB, Cassandra, HBase, and Elasticsearch.
A Document Database Example
The way these work varies wildly depending on the data model they are using. This is getting a little too deep for this article, but there are lots of ways to represent data besides the tables we looked at earlier.
Let’s use JSON as an example (it’s a common format for representing objects, which for some reason they call “documents”).
Instead of SELECTing from a table, we might simply ask for all songs by the Eurythmics like this:
database.collection("Music").find({artist_name: "Eurythmics"})And what we would get back would be a collection of “documents” that might look like this:
{
"SongID": "1983-002-XY",
"artist_name": "Eurythmics",
"song": "Sweet Dreams"
"album": "Sweet Dreams",
"year": 1983
}
Why is this useful?
Well, for one thing this approach to storing data makes it much simpler to make changes.
Let’s say we wanted to add the lyrics to the songs where we have them, but also provide some hints as to the structure, verses, chorus, etc.
It’s a lot simpler to add this to a JSON document:
{
"SongID": "1983-002-XY",
"artist_name": "Eurythmics",
"song": "Sweet Dreams"
"album": "Sweet Dreams",
"year": 1983,
"lyrics": {
"verse1": [
"Sweet dreams are made of this",
"Who am I to disagree?",
"I've traveled the world and the seven seas",
"Everybody's looking for something"
],
"chorus": [
"Some of them want to use you",
"Some of them want to get used by you",
"Some of them want to abuse you",
"Some of them want to be abused"
],
"verse2": [
"Sweet dreams are made of this",
"Who am I to disagree?",
"I've traveled the world and the seven seas",
"Everybody's looking for something"
],
"bridge": [
"Hold your head up, keep your head up, movin' on",
"Hold your head up, movin' on, keep your head up, movin' on
]
}
}So what this means is you can have a whole collection of JSON documents, each of which likely has some core fields in it that are common to them all.
But – lots of the documents have all sorts of extras added at different times for different purposes.
This is much harder to do in a rigid table structure.
Speed
Another feature – this sort of database is typically designed to be very fast to make updates to, as the data can be distributed across multiple servers (each holding some of the data).
For a completely different example, consider the database of tweets behind Twitter. If every Tweet was held in a single large “Tweets” database table … it wouldn’t work. Period.
There are hundreds of millions of tweets “sent” every day. (“Sent”in this case means “written to a database, where other people can see it.”) If that was a single humungous great table of tweets it would set the poor server on fire trying to keep up.
So – the solution there is to spread the load across multiple servers. Updates in one place might be visible to me immediately, but visible to you slightly later as we get delays in seeing what’s on different servers.
Does that matter? Not in this case, right? No-one really cares if some people see tweets slightly later or in a slightly different sequence.
For some real-time, mission-critical applications, the ACID approach really matters. For others, the BASE approach is more suitable.
Jargon Alert: BASE stands for Basically Available, Soft state, Eventually consistent. Essentially, you trade off some of the consistency for high availability and rapid updates. Changes flow through and eventually the picture is consistent for everybody. (I joked at work once that our financials demonstrated "eventual consistency". Went over well with the techies. The CFO was less amused.)
Let’s Wrap This Up
OK, so to summarize all that a bit.
There are lots of databases. Some of the key distinctions between the types is whether they are optimized for structured or unstructured data, for consistency or for speed.
There’s lots more of course (there always is).
Some databases are designed to be optimal for searching really big datasets. Some databases are optimized for AI tasks where data is stored in vectors (Pinecone is a good example of this). Some are open-source, some proprietary, and so on.
The choice will depend on many factors in the design of a computer system, and often more than one database type will be used in different parts of a complex system.
Before you go…
One of the inevitable consequences of the oceans of unstructured data being produced these days is new techniques and tools being created to manage (or at least, try to make some sense of) all this. That’s where terms like Data Lake, Data Warehouse, and Big Data Analytics start to come in … and that’s the subject of our next article…