

You may have heard the terms “clean room”, “data room” (or even “clean data room”) being bandied about, and it’s often clear from the conversation that they are some sort of “safe space” for personal data – a neutral Switzerland maybe – but how exactly does this work?
The Short Version
A data clean room is a secure environment that allows for the anonymized and aggregated analysis of data from multiple sources, providing valuable insights while maintaining user privacy and data security.
Think about it this way: identifiable data goes in, secure processes anonymize and aggregate that data, then authorized parties get to look at this newly “cleaned” data only.
A very common usage of this is for advertisers – they can get an aggregated output without individual identifiers, which can be shared with publishers or ad networks to inform a campaign. (One of the first companies to create an industrialized version of a clean data room was Google, with its Ads Data Hub in 2017.)
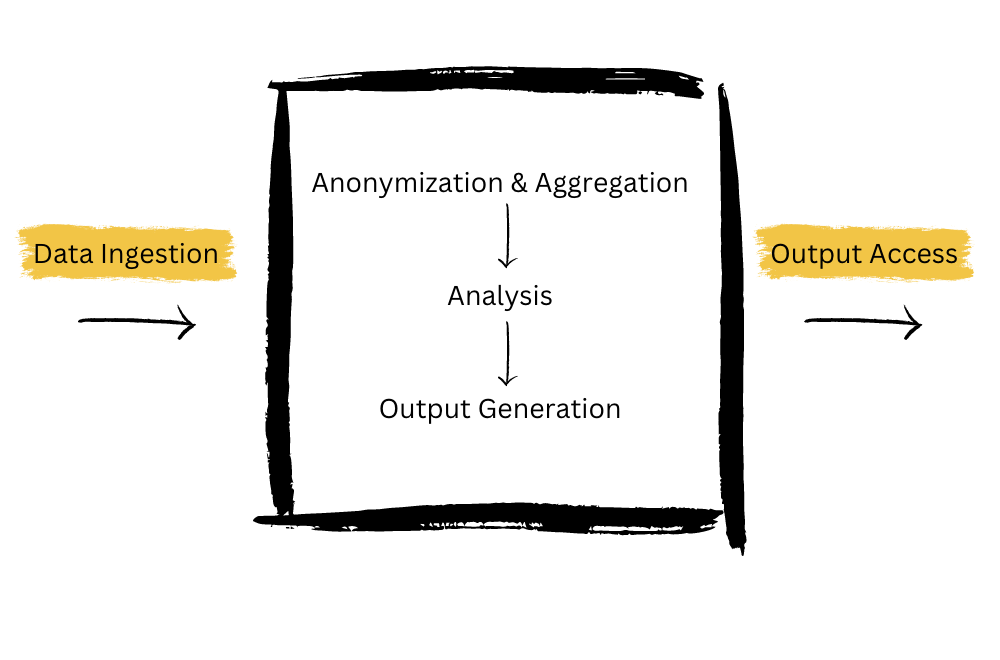
The steps are simple enough in theory:
- Each party uploads their (encrypted) sensitive data to the clean room
- The data is anonymized and aggregated to protect individual-level information
- A neutral third-party, often a consultant or specialized software, analyzes the data according to the agreed-upon questions or metrics
- The results of the analysis are shared with the interested parties. The raw data and the interim steps are not
The Longer Version
OK, let’s take a look at each of those steps in turn.
Data Ingestion
“Ingesting” is a term used to make loading data sound interesting. Spoiler: it’s still not interesting.
All this means is there is a controlled way for data to be loaded into the clean room system. Typically this will be encrypted so only the agreed people (who have the decryption keys) can read the data in the clean room.
There might be some modification at this point, such as extracting only certain data from the incoming stream, adjusting data from multiple sources so they have the same format and so on.
Anonymization and Aggregation
Remember the goal here is to get at all that sweet, sweet data without being able to identify any individual humans. Both anonymization and aggregation help achieve this, but in very different ways.
Anonymization
The idea here is to mask the data so that even Sherlock Holmes couldn’t work out who these individuals are. There are bunch of techniques that can be used separately or together:
- Literally mask the data: Replace sensitive data with consistent but artificial data. For example, replacing a customers name with a randomly-generated pseudonym. (I used to work at, um, a Large Financial Institution, and this technique was built into every database copy we developers could look at.)
- Generalize it: Don’t need the data to be that precise? If you replace, say, a specific age with an age-range, or a specific location with a broader region, this makes identification of specific individuals harder.
- Turn Up The Noise: This may seem counterintuitive, but it can be useful to add random data (or noise) to the original data. A simple example: looking at a bunch of people’s salaries? You could add or subtract a random amount from every salary. If that’s applied truly randomly, then you can’t determine an individual’s salary, but the overall dataset still has (within predictable limits) the same average salary, the overall distribution is essentially the same, etc. Clearly – that’s some complicated probability distribution magic and needs a lot of care to ensure the data isn’t compromised. But that’s why you hire hotshot data scientists.
- Data Swapping: Different version of adding noise – you can create permutations by rearranging the data values between records (person 1 swaps addresses with person 2, person 7 gets person 8’s salary, etc). This way all the data is still there, and can be analyzed in aggregate, but good luck unscrambling that egg.
Aggregation
A very common technique to hide the identifiable data is to remove the details.
All of the choices here depend on the end use for the data (outside the clean room). If individual data isn’t needed, but only say, aggregated data by groups, then we can group up the data before passing it on.
Only need the average height by town for your analysis? Calculate that average on the uncleaned data inside the clean room, but then only pass on the average so there is no individual record available that could be used to identify someone.
Sidebar It might seem reasonable to ask why all these techniques are needed. Surely if you've got (say) no names, and all the addresses are turned into zip codes only, surely no-on can identify an individual from that? Well, that might be true, but we always need to assume that someone else is going to get their hands on our data. Think of this as red-teaming: how could someone else re-identify people? Let's say we have medical information about patients in a hospital that has been anonymized for a research project. This anonymized dataset includes age ranges, gender, zip code, and the type of illness the patients have. Let's say a third party acquires another dataset, say from a local pharmacy. It has information about prescription drugs sold, along with the age and zip code of the buyers, but also without any direct identifiers like names or addresses. No identifiers, right? Ah - but. Correlation is our tool here. Let's say there's only one 50-60 year-old male in a certain zip code who bought a specific prescription drug in the pharmacy dataset. There's also only one 50-60 year-old male with an illness for which that drug is prescribed in the hospital dataset. Now we still don't have that person's name yet, but we can infer they are the same person, so we've lost some anonymity. So what other data can we start to link that to, and ... eventually we get to the actual human involved. Elementary, my dear Watson.
Analysis
Remember, we’re still in the clean room here.
Those data scientists still have work to do. The anonymized and aggregated data now needs to be analyzed in more detail. What insights can be gleaned?
This is where the marketing teams get very excited as you can combine data in different ways and look for patterns that allow you to determine how effective an ad campaign was (“people who saw this ad had a 20% greater propensity to buy one of the blue widgets”) and so on.

Output Preparation
Exactly as it sounds! Now that the analysis is over and we’ve got together the insights that are most relevant, we can package this up for distribution outside the clean room.
This should be no big surprise at this point – that output is typically higher-level, aggregated data, with no individually-identifiable data in there.
Output Access
And finally (drum roll please) even that aggregated, anonymized reporting is made available in a controlled way – only the authorized, agreed users get to access the dataset coming out of the clean room.
Who are these exalted few? Well, they may be the original groups that supplied the data, or a new set of users who can use the insights without getting a look at individual data (think of advertisers and ad platforms getting to see actionable insights in an anonymized way.)
Want a real life, non-advertising example?
We used to do this with operational data. A bunch of similarly-sized institutions would share tech budget data with a third party. We’d get back aggregate numbers that could be used to prove that on average our competitors were spending more than we were. So our budget should totally be increased next year.
Ahem.
(This is a form of Chatham House rules – everyone puts their data in, a trusted third party aggregates the data, and everyone gets the aggregate info but nothing that can be attributed).
So What Questions Should You Be Asking?
There’s no way we can list out everything you should be asking, especially as each case has unique quirks. But this should hopefully give you a running start:
What data is going into the clean room? Is it all necessary and relevant to the agreed-upon questions or metrics? (if not needed - don't load in the first place!) How is data being encrypted before it's loaded into the clean room? What processes are in place for anonymizing the data? Which specific techniques are being used (e.g., data masking, generalization, adding noise, data swapping)? How is data aggregation being carried out? Have we red-teamed any risks of re-identification from the aggregated data? Who exactly is performing the data analysis within the clean room? What measures are in place to ensure that the analysis doesn't inadvertently expose individual-level information? How is the output prepared? Is there any chance that sensitive information could inadvertently be included in the output? Who has access to the final output? What controls are in place to ensure that only the right people can access it? How are the data and the analysis stored and disposed of after the process is completed? Do we have a plan in place in case of a data breach or unauthorized access to the data clean room? (Spoiler alert - breaches happen all the time. Have a plan. Don't wing it) Is any of this data being transferred cross-border? (Can open, worms everywhere....)
If the clean room is being provided by a third party, there are some additional questions you could ask:
Does the data clean room provider have any audits or certifications that verify their data security practices? What is the policy for handling inquiries, complaints, or data subject requests related to the data processed in the clean room? How are updates to data privacy laws and regulations monitored and implemented within the clean room implementation? What contractual protections are in place with the data clean room provider and other involved parties?
Take Aways
All right, that’s all for now on clean rooms! Here’s a quick recap:
- A clean room is a secure environment that allows for the anonymized and aggregated analysis of data from multiple sources, providing valuable insights while maintaining user privacy and data security.
- The process involves safely loading the data, anonymization and aggregation (to protect individual-level information), analysis by a neutral third-party, and sharing of the results without exposing the raw data or interim steps.
- We anonymize data by techniques like data masking, generalization, adding noise, and data swapping. Aggregation involves the consolidation of data to create general insights without exposing individual-level information. The goal is to create insights from the data that won’t reveal any individual identities, even when the data might be combined with other datasets.
- It’s important to ask a lot of pointed questions. Who is doing what, what risks are there for re-identification, do we absolutely need all the data we’re loading?
Just One More Thing
(An Entirely Unnecessary Historical Digression)
Feel free to skip this part completely, I won’t be offended!
So clearly we’re talking about processes, and controlled access – why is it called a “clean room”?
It’s partly metaphor, partly a historical term.
Way back when, companies that were engaging in due diligence used to use actual data rooms – physical rooms where books and records of the firm where shared, and only authorized people would have access to get into the room and review only those documents.
Same concept applies today for firms engaged in M&A activities – although of course it’s usually secure access to online records now.
But here’s another thing. The term “clean room” has a different usage in the world of software development.
If you want to build software to do something very much (or even exactly like your competitor) without violating copyright, engineers can write up detailed specs of exactly what they want the software to do (but not how to do it).
Then – separate engineers go to work in a “clean room”. In that environment they have no access to the competitor software and work hard, traditionally fueled entirely by pizza and cola, to create something entirely by themselves, that will do exactly what the spec says.
Having a “clean” room, with access logs showing who worked on what and when, gives you some protection as it allows you to say “yes, our code does exactly the same thing, but we built it ourselves without ever looking at your code.”
Fun fact This is a key plot point in the first season of the AMC series "Halt and Catch Fire" about life in the crazy, high-drama world of .... building IBM PC clones in the 1980s. No, I don't know how that got green-lit either...